A Subset of Database Systems (and Why They're Interesting), Part 1
Introduction
As I’m learning about many different, very interesting, fun and zesty database systems, I’ve realized that it’s difficult to realize what exactly is important about these database systems from a technical perspective. Of course, my eventual goal is to have the wisdom of an experienced databases researcher (e.g. my advisor) and innately understand the important features of a database system after a quick skim of its documentation and source code. However, I’m obviously not there yet, and I thought this would be potentially insightful and fun to create as I learned about the significance of cool database systems!
PostgreSQL
Development of the PostgreSQL database management system began in the mid-1980s, and was an effort primarily led by MIT professor Mike Stonebreaker, a man so cool he’s got his own Wikipedia article. Originally, PostgreSQL was designed to be a one-size-fits-all database system. PostgreSQL is the pioneering database system of supporting abstract data types: both complex objects (e.g. nested tuples) and user defined data types (UDTs). PostgreSQL also has an thriving extension ecosystem, with its support for UDTs, user defined functions, user defined aggregates, and a variety of hooks (essentially, function pointers) that are used to overwrite various components of the PostgreSQL DBMS. Outside of extensibility, PostgreSQL also provides a rich set of features, including a variety of indexes, parallel execution support, and multi-version concurrency control*. However, it’s important to note that Andy Pavlo attacks PostgreSQL’s MVCC in another blog post. Lastly, PostgreSQL has a vibrant open source community of maintainers and feature developers. PostgreSQL’s impact on the databases community is incredible, as many prevailing ideas of DBMS development and implementation today are based on PostgreSQL.
*: Multi-version concurrency control: a method of providing concurrent access to a database by storing multiple versions of the database state.
Snowflake
Snowflake is a powerful, state-of-the-art online analytical processing (OLAP) data warehouse, built with cloud technology from the ground up. For instance, Snowflake uses AWS S3 as its persistent storage layer, and sets of AWS EC2 instances as its compute layer. One of Snowflake’s main goals is supporting high elasticity. To support elasticity, Snowflake separates their compute layer, persistent storage layer, and ephemeral storage layer, where the ephemeral storage layer stores intermediate data used during compute. All of these layers are individually scalable. For example, if the query planner determines that a large amount of data needs to be processed, the compute layer can scale appropriately by allocating more worker nodes to accelerate the query performance. Snowflake also uses its ephemeral storage layer as a write-through cache for its persistent storage layer. This disaggreated storage technique allows Snowflake to take advantage of cloud storage while still being highly performant. Another one of Snowflake’s advantages is that it provides its product as-a-service, which is tech jargon for allowing customers to use a database system without the required hardware or a software installation. Ultimately, Snowflake is one of the best cloud-native, scalable OLAP DBMSs in the industry.
Databricks Lakehouse
Databricks Lakehouse is a data management platform that combines techniques used in the design of both data warehouses and data lakes. Lakehouse includes four layers in their software stack, which are:
- Cloud Storage Layer: Users can choose their own cloud storage provider to persistently store their data, such as Amazon Web Service’s S3 or Google Cloud Storage.
- Data Management Layer: Lakehouse uses Delta Lake, an open-source data management platform that provides different features such as ACID transactions, data versioning, and metadata support, in order to manage their raw storage layer.
- Execution Engine Layer: This layer is responsible for executing queries in Lakehouse. It consists of runtime clusters, that contain two types of nodes, a driver node that directs other nodes and directs execution, and executor nodes that conduct data processing. The nodes are implemented as cloud computing VMs (e.g. AWS EC2 instances). The driver runs query planning, optimizing, and scheduling tasks, while each of the executor nodes run a single threaded execution engine called Photon, which conducts a series of data processing tasks.
- User Interface Layer: Databricks provides a UI layer for users to submit SQL queries, or interface with Lakehouse by using the Apache Spark Dataframes API.
One of the newer developments of the Lakehouse product is Photon, a single-threaded vectorized execution engine that was developed for high-performance query processing. Photon is a pull-based query engine, which means that its implementation pulls data from operators. One of the reasons that Photon is incredibly fast is because of its usage of precompiled execution kernels, which are vectorized C++ functions that execute loops over a batch of data. These functions can be specialized via C++ templates. Ultimately, Photon has helped Databricks be the current top performer of the official 100TB TPC-DS benchmark.
Note: It is technically possible to run Databricks without Photon’s data acceleration. However, I only discuss the Databricks Lakehouse platform with Photon enabled.
Google Spanner
Spanner, a globally distributed, NewSQL DBMS developed by Google Cloud starting in 2007, is significant in the databases research sphere because it offers both a strict serializability and external consistency guarantee, without sacrificing performance, on a very large scale. In other words, while dealing with transactions involving trillions of rows and hundreds of datacenters, Spanner manages to globally order transactions and guarantee that the results of these transactions reflect their global order. It achieves this guarantee by providing globally-meaningful commit timestamps to each transaction, which reflect the serialization order. The transaction timestamps reflect the following invariant: if the transaction T2 starts after T1 commits, then the commit timestamp for T1 is lower than T2. Spanner implements this invariant via the TrueTime API, which contains one main method, TT.now(), which returns an interval of the global time of when it was invoked. TrueTime is implemented by a set of time master machines per datacenter and a timeslave daemon per machine. The time master machines are equipped either with GPS receivers or atomic clocks, and serve to collect the global time when polled. The timeslave daemon determines the time by polling different masters, ejecting liars and faulty clocks, and then, syncing its local machine clock to the time determined by the masters. Spanner implements multi-version concurrency control, so its read-only transactions are implemented by collecting the timestamp and reading the data at that specific timestamp. Read-write transactions are synchronized via 2PL, where timestamps are grabbed after the write locks have been obtained. Overall, Spanner’s strict serializability guarantee and the methods used to implement it have made a significant impact on the databases research sphere.
Amazon DynamoDB
DynamoDB is a highly available key-value store released in 2012 by Amazon Web Services. Two of its main goals are to provide 24/7 availability and meet its services’ stringent latency requirements. To maintain its high availability and performance, DynamoDB sacrifices a true consistency guarantee, opting instead for an eventual consistency guarantee, which means that all updates will eventually be reflected onto all the replica nodes in its distributed system. DynamoDB is a distributed system, and partitions its data across multiple nodes using a consistent hashing technnique. However, the original consistent hashing algorithm randomly assigns the position for each node on the ring, which results in a non-uniform data and load distribution. To combat this, DynamoDB assigns each node in the consistent hashing ring to multiple positions, which provides incremental scalabilty. DynamoDB also supports highly concurrent, never failing writes by keeping multiple versions of immutable update data at a time, then using vector clocks to order these updates. It also reconciles these versions back into one authoritative version during reads. Lastly, DynamoDB employs several techniques to remain fault tolerant, including a “sloppy quorum” protocol to execute distributed get() and put() operations in the case of temporary failures and Merkle trees to reconstruct database state in the case of permament failures. DynamoDB has resulted in high research impact on both the distributed system and database system fields, and won a SigOps Hall of Fame award in 2017. Personally, I also adore DynamoDB as a system for taking a very specific set of design constraints and goals, and creating a system that meets their needs.
DuckDB
DuckDB is an embeddable OLAP DBMS developed by researchers at Centrum Wiskunde & Informatica (CWI), a computer science research institute in the Netherlands. It aims to provide a solution for embeddable analytical data management, which is useful in the fields of data analytics and edge computing. One of the key features of DuckDB is their customized vector format. DuckDB uses several different vector representations, which allow it to store a compressed physical version of data, and push compressed data through their execution engine. 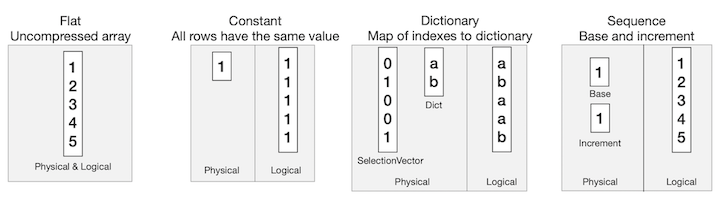 DuckDB’s push-based execution engine is designed to support high amounts of parallelism. For instance, AWS instances running DuckDB can use up to 192 cores. In their implementation, their
DuckDB’s push-based execution engine is designed to support high amounts of parallelism. For instance, AWS instances running DuckDB can use up to 192 cores. In their implementation, their Source (getting data) and Sink (combining results from operators) methods are parallelism aware, but the operator methods themselves are not parallelism aware. One advantage of this is that handling the movement of data in a central location allows for optimizations. One example of this is scan sharing, implemented by pushing the results of operators into multiple sinks. DuckDB also uses a morsel-driven parallelism model, adapted from TUM’s database system HyPeR. Overall, DuckDB’s impact on the industry is very noticeable, especially given how new of a system it is!
Conclusion
Ultimately, this turned into a “things I personally found interesting about database systems I’ve seen recently” post as opposed to “this are the de-facto features that make these databases systems special” post; however, I like this style better! If you read the post, I hope you learned something, and feel free to give me any feedback or let me know if I got anything wrong.
Acknowledgements
I would like to thank my friend Yaotian Feng for reading through this article and providing helpful feedback!
References
- Looking Back at Postgres
- Postgres 15 Docs
- Building An Elastic Query Engine on Disaggregated Storage
- The Snowflake Elastic Data Warehouse
- Photon: A Fast Query Engine for Lakehouse Systems
- Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
- Google Cloud Spanner Docs
- Spanner: Google’s Globally-Distributed Database
- Dynamo: Amazon’s Highly Available Key-value Store
- Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service
- DuckDB: an Embeddable Analytical Database
- Andy Pavlo’s 15-721 Spring 2023 Lectures
Enjoy Reading This Article?
Here are some more articles you might like to read next: